
介绍
Lucene 是一个基于 Java 的开源全文信息检索工具包,目前业界常用的 Elasticsearch、Solr 都是基于 Lucene 构建其全文检索能力。
完整的搜索过程
我们在使用搜索引擎的时候,对搜索的感官认识是,搜索引擎通过爬虫爬取互联网数据,建立成索引后,通过排序算法返回给使用搜索引擎的用户。
而对 Lucene 来说则关注搜索过程中的索引创建、存储、搜索、排序等过程。
索引文件
下图是文档与倒排索引的简要展示图:
左侧的文档的一系列字符串在右侧的索引文件中被记录为词典与文档位置,从而形成一个映射关系。
右侧的索引文件即为倒排索引。
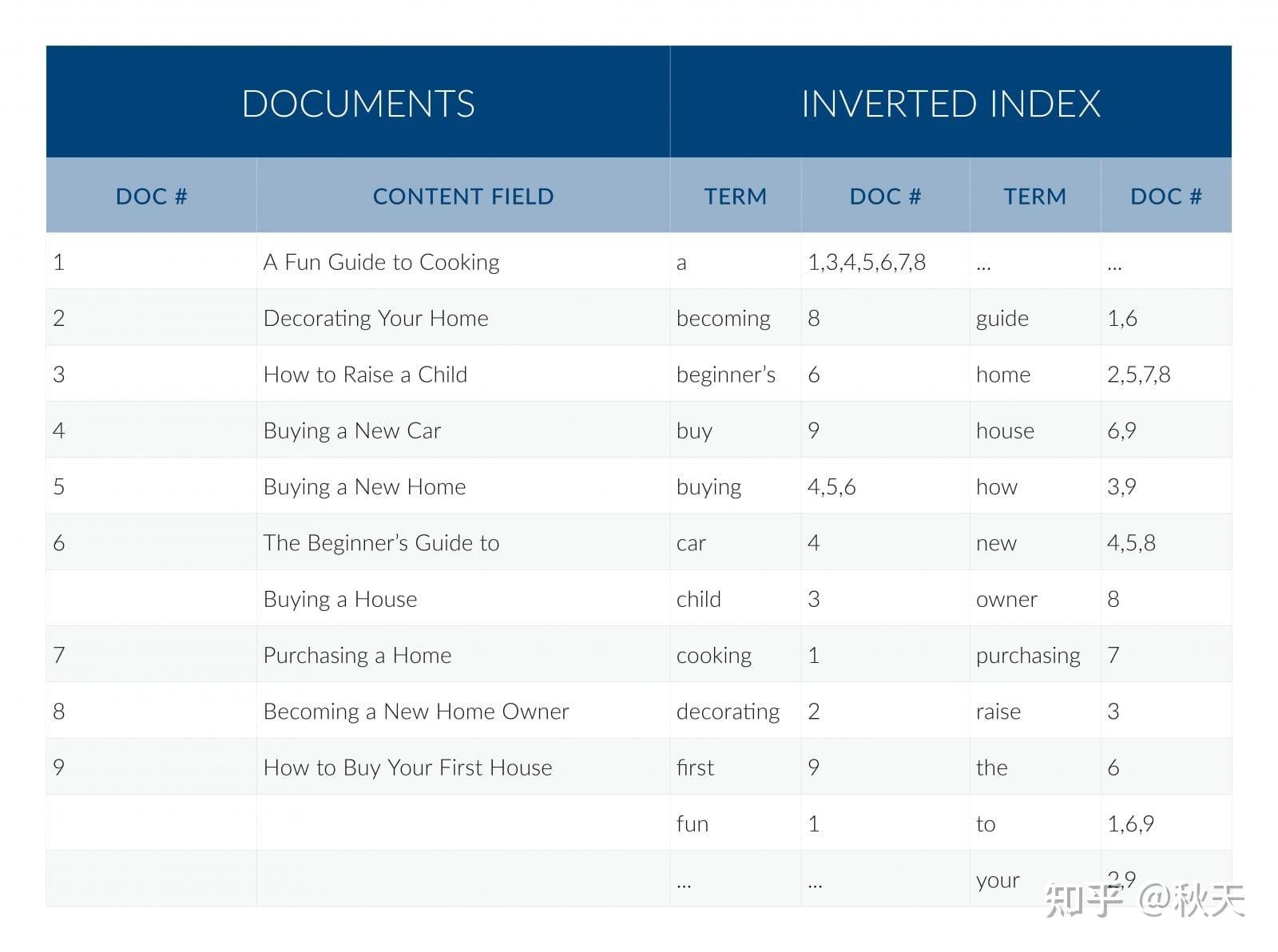
倒排索引
倒排索引的数据结构非常简明易懂:
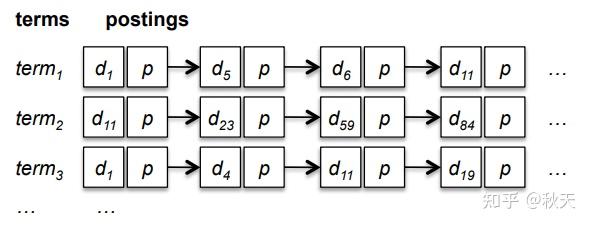
倒排索引数据结构
这种索引结构能够大大加快搜索速度,例如当用户搜索 term1 ,那么就可以查询 term1 对应的链表取出对应的文档。
当采用合并链表的方式则可以取出多个关键词形成的组合搜索。
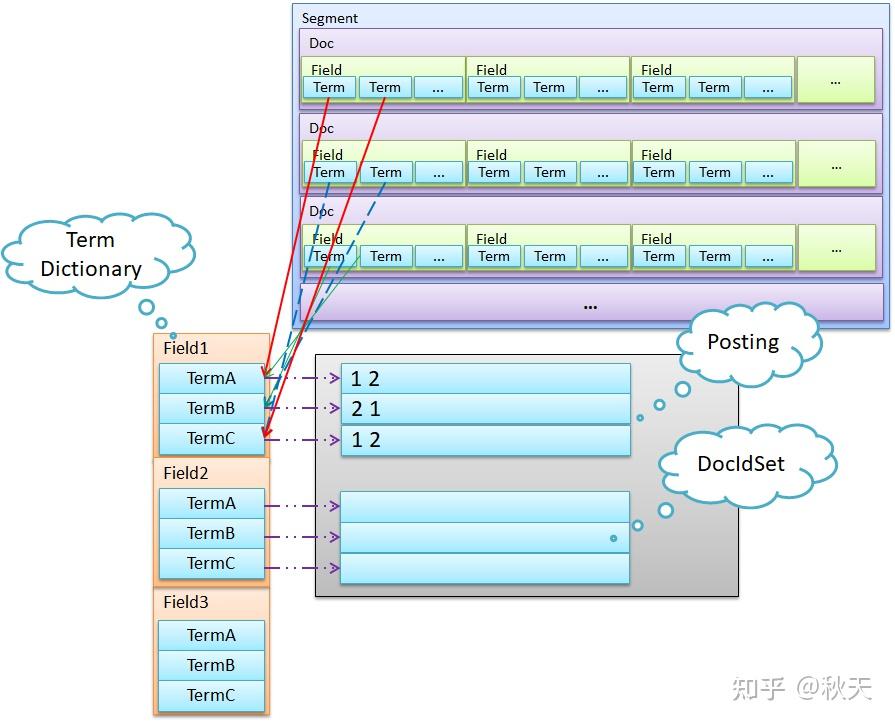
倒排索引数据结构展示
Lucene 将索引文件拆分为了多个文件,这里我们仅讨论倒排索引部分。Lucene 把用于存储 Term 的索引文件叫 Terms Index,它的后缀是 .tip ;把 Postings 信息分别存储在 .doc、.pay、.pox,分别记录 Postings 的 DocId 信息和Term的词频、Payload 信息、pox 是记录位置信息。Terms Dictionary 的文件后缀称为 .tim,它是Term与Postings的关系纽带,存储了Term 和其对应的 Postings 文件指针。
索引创建过程
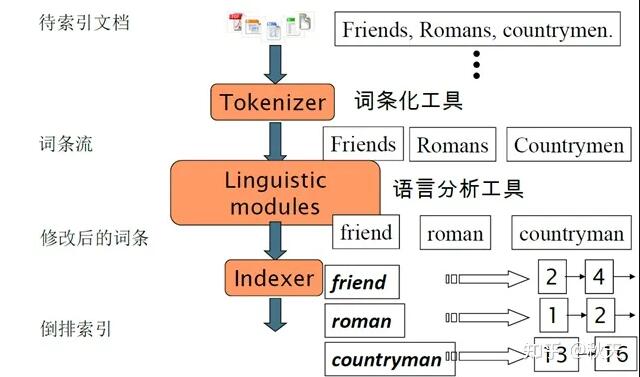
索引创建流程
Tokenizer 过程
● 把文档拆分为一个个单独的单词
● 去除标点符号
● 去除停词
Linguistic Processor 过程
● 转换为小写
● 缩减单次为词根,例如 cars ⇒ car
● 词干提取,例如 drove ⇒ drive
Indexer 过程
● 利用上一阶段获得的词结果(Term)创建字典
Term | Document ID |
friend | 1 |
roman | 1 |
countryman | 1 |
● 对字典进行排序
Term | Document ID |
countryman | 1 |
friend | 1 |
roman | 1 |
● 合并相同Term,并提取到倒排(posting list)链表中
● 存储 Term 的词频与位置
搜索过程
词法分析
主要用于识别单词与查询语法关键字(如 AND、OR、NOT等)
语法分析
依据语法规则生成查询的语法树
例如:lucene AND learned NOT Hadoop
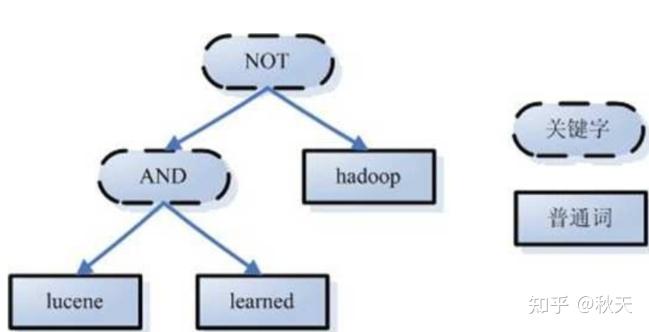
语法树
Linguistic Processor
与索引阶段类似,小写转换、词根缩减、词根转换等操作。
搜索算法
● 在倒排索引中找到对应的文档链表
● 合并 lucene、learn 链表
● 把合并后的链表与 hadoop 链表做差集,去除包含 hadoop 的文档,得到新的链表
计算 Term 权重
● Term Frequency(TF):Term 在文档中出现次数越大,相关性越高。
● Inverse Document Frequency(IDF):Term 在越多的文档中出现,相关性越低。
由此得到权重的计算公式:

计算文档相关性评分(计算余弦值)
如果把文档看作是 Term 的集合,每个 Term 都有一个权重,不同 Term 可以根据自己在文档中的权重来影响文档相关性的打分计算。
定义:Document = { term1,term2 ... termN }
那么可以得到文档的权重向量为:Document vector = { weight1,weight2 ... weightN }
如果把查询条件也看作一个文档,那么可以定义为:
Query = { term1,term2,... termN }
Query vector = { weight1,weight2 ... weightN }
如果把 Document 与 Query 放置到一个 N 维空间,每个 Term 为一个维度,那么可以得到:
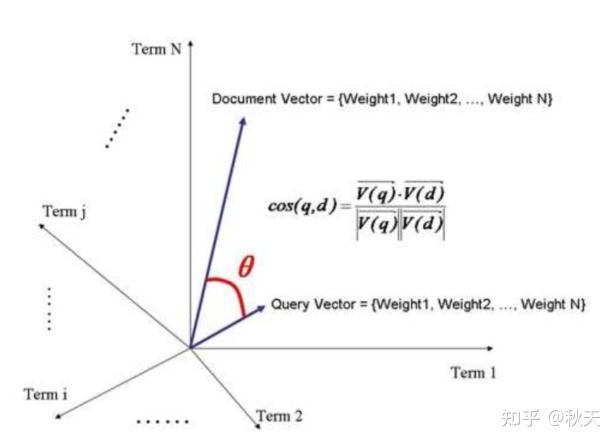
空间向量与余弦定理
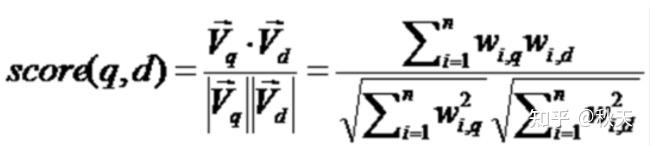
利用余弦定理打分
公式证明:
余弦函数:

在直角坐标系中,向量表示的三角形的余弦函数是怎么样的呢?下图中向量 a 用坐标 (x1, y1) 表示,向量 b 用坐标 (x2, y2) 表示。
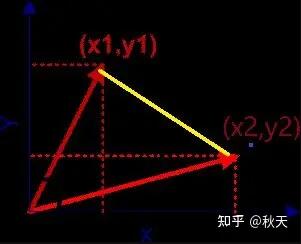
余弦计算方式
a、b 的长度可以分别用公式表示为:

那么可以用 c 表示 a、b 之间的长度(黄色线段):
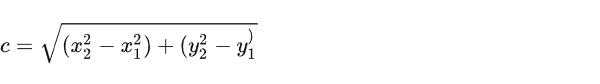
将 a、b、c 分别代入三角函数公式可以得到:
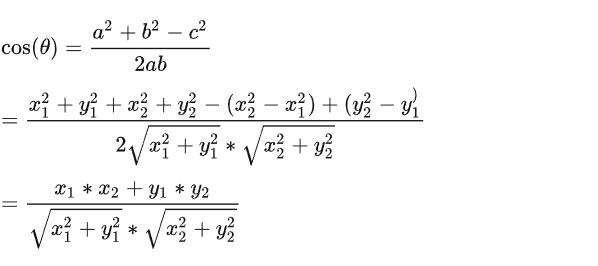
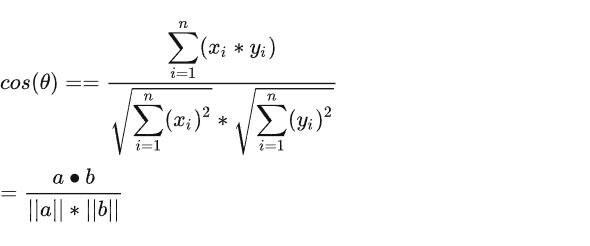
上面公式针对的是二维情况,如果映射到多维可以使用公式表示:
排序
依据余弦相似度公式计算出的分值进行结果排序。
参考资料:
使用余弦相似度算法计算文本相似度:
https://zhuanlan.zhihu.com/p/43396514
ES 中使用的相关性计算方法
在 TF-IDF 和 空间向量模型的基础上,增加了协调因子、字段长度归一化、Term 权重提升等功能。
字段长度归一化:
字段长度越短,认为其权重越高,例如 title 的权重比 body 更高。
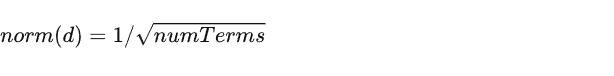
相关性计算公式
queryNorm:查询的规范化因子
coord:协调因子
norm:归一化值
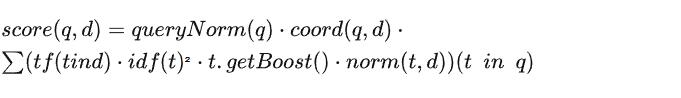
BM25
在 ES 5.0 后,相关性的计算方法可以使用 TF-IDF 改进版的 BM 25 算法(业界最优相关性算法)。
*词频饱和度(Term-Frequency Saturation*)
TF/IDF 和 BM25 同样使用逆向文档频率来区分普通词(不重要)和非普通词(重要),同样认为(文档里的某个词出现次数越频繁,文档与这个词就越相关。
不幸的是,普通词随处可见,实际上一个普通词在同一个文档中大量出现的作用会由于该词在 所有 文档中的大量出现而被抵消掉。
曾经有个时期,将最普通的词(或停词 )从索引中移除被认为是一种标准实践,TF/IDF 正是在这种背景下诞生的。TF/IDF 没有考虑词频上限的问题,因为高频停用词已经被移除了。
Elasticsearch 的 standard 标准分析器( string 字段默认使用)不会移除停用词,因为尽管这些词的重要性很低,但也不是毫无用处。这导致:在一个相当长的文档中,像 the 和 and 这样词出现的数量会高得离谱,以致它们的权重被人为放大。
另一方面,BM25 有一个上限,文档里出现 5 到 10 次的词会比那些只出现一两次的对相关度有着显著影响。但是如图 TF/IDF 与 BM25 的词频饱和度 所见,文档中出现 20 次的词几乎与那些出现上千次的词有着相同的影响。
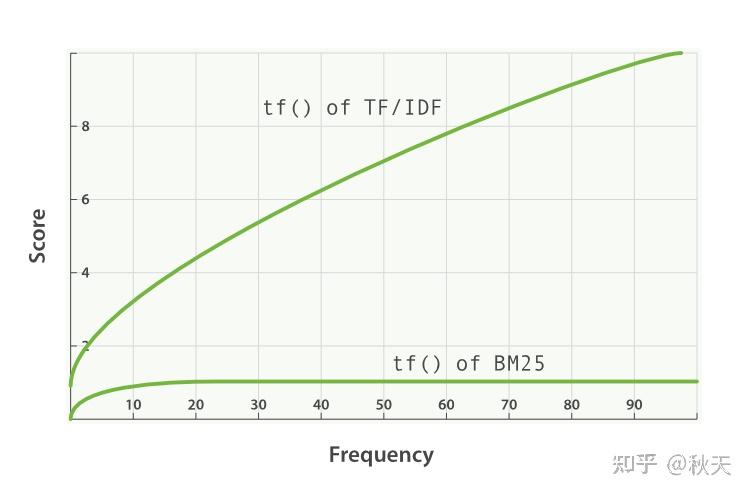
TF/IDF
*字段长度归一化(Field-length normalization*)
在 字段长归一化 中,我们提到过 Lucene 会认为较短字段比较长字段更重要:字段某个词的频度所带来的重要性会被这个字段长度抵消,但是实际的评分函数会将所有字段以同等方式对待。它认为所有较短的 title 字段比所有较长的 body 字段更重要。
BM25 当然也认为较短字段应该有更多的权重,但是它会分别考虑每个字段内容的平均长度,这样就能区分短 title 字段和长 title 字段。
在 查询时权重提升 中,已经说过 title 字段因为其长度比 body 字段自然有更高的权重提升值。由于字段长度的差异只能应用于单字段,这种自然的权重提升会在使用 BM25 时消失。
*BM25 调优*
不像 TF/IDF ,BM25 有一个比较好的特性就是它提供了两个可调参数:
● k1
这个参数控制着词频结果在词频饱和度中的上升速度。默认值为 1.2。值越小饱和度变化越快,值越大饱和度变化越慢。
● b
这个参数控制着字段长归一值所起的作用, 0.0 会禁用归一化, 1.0 会启用完全归一化。默认值为 0.75。
在实践中,调试 BM25 是另外一回事, k1 和 b 的默认值适用于绝大多数文档集合,但最优值还是会因为文档集不同而有所区别,为了找到文档集合的最优值,就必须对参数进行反复修改验证。
转载地址:https://zhuanlan.zhihu.com/p/497929354
 返回列表
返回列表
 电话
电话
 地址
地址
